Coffee Route
Programming 
Description🔗
The recent work-from-home trend has given people the freedom to choose where they want to work and to get things done on their own time. However, for many, staying at home all day is a drag and going to the office is a chore, so instead they prefer to grab their laptops and hit the streets: cafés offer the opportunity to have a coffee, take in the ambience, let the sounds of others' dispassionate Zoom meetings and pained typing drown out your own existential dread born from working in a late-stage capitalist hellhole, grab a bite, meet up their friends, and otherwise engage in productivity. Coffee Route is a way for them to find workspaces that offer the sort of ambience and interaction opportunities that many young professionals are looking for, without the need to pay for a WeWork membership or to rent a permanent workspace.
Coffee Route presents a potentially interesting paradigm shift from the usual method: rather than searching Google Maps, reading all the reviews, picking a place, realizing it's too far away, picking a different place, ad nauseam, it instead allows one to describe the class of desirable routes in more abstract terms, without fixating on any one place or route and without giving way to the analysis paralysis that such searches usually engender. This paradigm shift appears similar to the shift from imperative to declarative programming patterns, and would seem to apply to a broader class of search queries than just "what coffee shops are nearby". Coffee Route will hopefully prove a valuable entrypoint into a better understanding of the potential of searching over general descriptions of desired experiences instead of specific locations.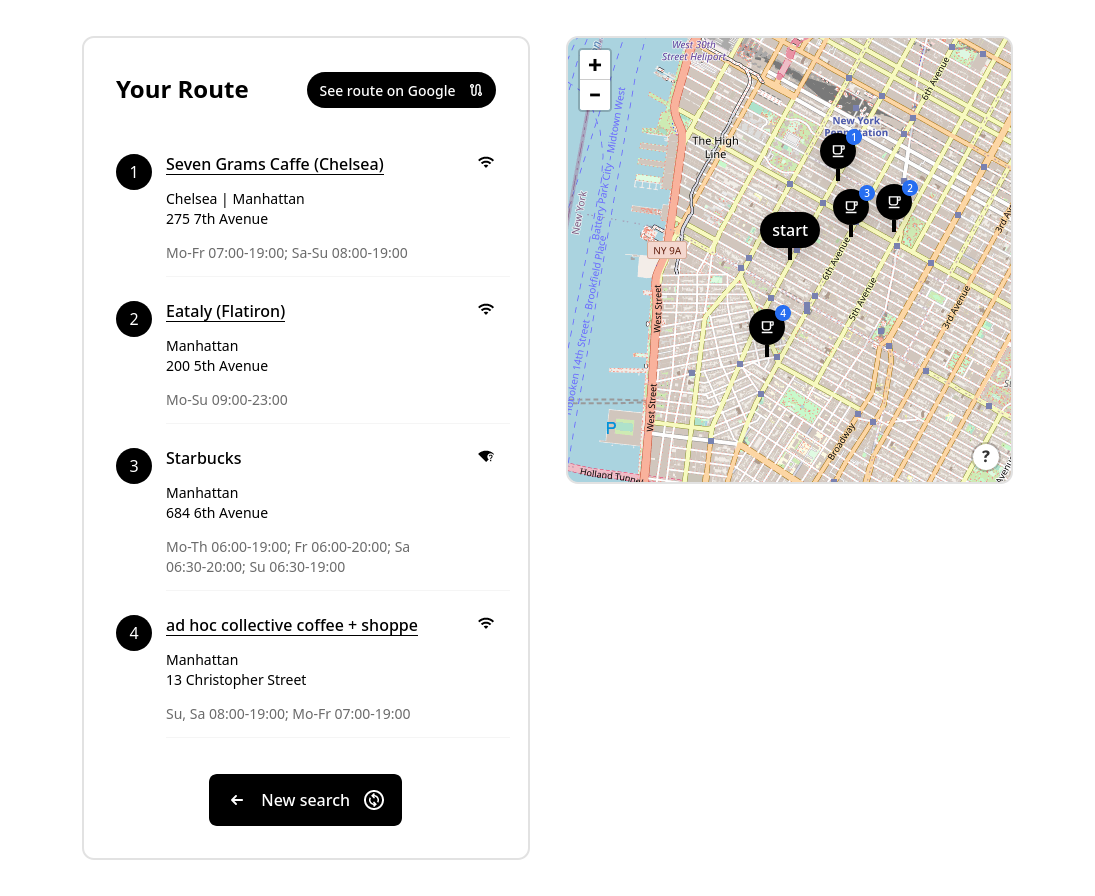
Method🔗
Coffee Route is a Preact webapp that utilizes data from OpenStreetMap to find cafés within a certain distance of a selected point (either a dropped pin or the geolocation marker of the user). An OverpassQL query is constructed based on user preferences, and is then executed against an OverpassAPI instance. The resulting information is then enriched with reverse-geocoding information from OpenStreetMap's Nominatim service to augment the address information provided from the regular dataset. A final filter is passed over the enriched data, fulfilling the remainder of the user preferences (such as open times and the existence of free wifi), before the data is reordered according to the shortest route from the start location. This is achieved using a brute-force travelling salesman solver, as the number of possible stops currently cannot go above the point at which a more sophisticated algorithm would achieve meaningfully better performance. The sorted list is then presented and plotted on the map, where users can see the proposed route and generate a Google Maps link for routing.
Points of interest🔗
Familiar UI🔗
Given that we're exploring a relatively new space, I wanted to minimize the amount of friction and confusion that users might experience with the interface by piggybacking off designs users are likely to already be familiar with. To that end, I made sure to employ modern UI/UX trends while keeping the browser builtins for the form controls; that way, users would recognize the inputs as those specific to their operating system while still interacting with a modern-looking website. And, since this is ultimately a geospatial interface, I chose to style everything using Uber's open source design language and components, which should hopefully offer some familiarity given the similar contexts (I also chose it because of how lightweight it is, but more on that later).
Lightweight bundle🔗
The choice of technologies is intentionally optimized for a minimal bundle size and load times on mobile networks, while still maintaining ease of development. Using tools like Bundlephobia, I was able to analyze the relative weights of particular libraries, which I could then consider alongside the other tradeoffs. For example, when deciding which mapping library to use, I chose Leaflet over the significantly more modern MapboxGL despite the better tooling and library interop of the latter, because the former has a significantly smaller bundle size and noticeably better performance on mobile devices. Similarly, Baseweb was selected because, in addition to the aforementioned benefits of Uber's familiarity, it is a significantly lighter dependency and offers a CSS-in-JS model that would allow for fewer file loads and better tree-shaking of styles than traditional tooling.
Open data🔗
From the UI kit to the map tiles, Coffee Route relies entirely on open source libraries and data: the tiles, geocoding, and geospatial data are all provided by OpenStreetMap; the slippy map is painted and made interactive using Leaflet; the UI uses Uber's Base Web design system and is rendered using Preact! Since all of the data is sourced from OpenStreetMap, users can contribute data improvements to the open dataset, benefiting both direct users of Coffee Route and anyone else that uses the OpenStreetMap dataset. Using
Things I learned🔗
Product engineering🔗
The majority of my clients come to me with explicit requests for features/solutions, or with less defined requests but for established products, so it's quite rare for me to work directly with the end users to determine what exactly needs to be built. This project has been a nice exercise in product design and engineering, requiring me to talk directly to end users to see what works and what doesn't and what direction things should be going in. Working with my friend acting as my PM has been a nice way to keep my product skills sharp, always trying to strike the right balance between the minimal amount of work that will get us to the next iteration and anticipating the next feature requests without having to scrap/refactor too much.
Where to next🔗
This project is still very much in the MVP stage. It probably won't go anywhere in its current state, but I remain confident in its exploratory value, and it's definitely proving a useful practice exercise to work on skills that I don't get to use in my day-to-day as often. I'd like to get the project into a "set it and forget it" state where it can be passively monetized and worked on incrementally when I have the free time, so my next goal will be to productionize the MVP with a locked-in feature set and then set up the requisite infrastructure to let it run indefinitely without oversight.
More natural querying🔗
One thing that we're very interested in looking at is making the way we describe these declarative geospatial queries more natural and intuitive to users. To that end, we're exploring the use of LLMs to help make the jump from (restricted) natural language queries to something that can be processed by a database or geospatial index. One of the ways we're thinking this might be achieved is by, rather than training the LLM to output the query directly, instead coaxing it to only give responses that have the requisite shapes and properties (a simple example of this may be OpenAI's efforts to have their GPT-4 model output proper JSON, though we're looking to complicate matters significantly).